
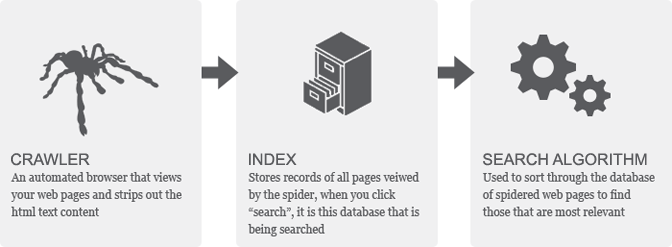
Search engine indexing is the process of a search engine collecting, parses (scrapes the content!) and stores data for use by the search engine this is what is called a Search engine index.
Yes, this means that the search engines (Google, BING, Yandex, Baidu etc etc) all take effectively a photocopy of each and every webpage on the internet, and stores it on their own servers. It is THEN that they do their secret analysis.
The actual search engine index is this place where all that data the search engine has collected and “photocopied” is stored.
It is from this search engine index that provides the results for search queries, and pages that are stored within the search engine index that appear on the search engine results page.
Without a search engine index, the search engine would take considerable amounts of time and effort each time a search query was initiated, as the search engine would have to search not only every web page or piece of data that has to do with the particular keyword used in the search query, but every other piece of information it has access to, to ensure that it is not missing something that has something to do with the particular keyword.
Spiders and Crawlers, what’s the difference?
Search engine spiders, also called search engine crawlers, (yes they are the same thing just different reference words) are how the search engine index gets its information, as well as keeping it up to date and free of spam.
There are many different parts to a search engine index, such as design factors and data structures.
The design factors of a search engine index design or outline the architecture of the index and decide how the index actually works.
The parts all combine to create the working search engine index, and include:
- Merge factors, which decide how the information enters the index, deciding whether the data is new data or data that is being updated.
Index size, which pertains to the amount of computer space necessary to support the index. - Storage techniques, which is the decision of how the information should be stored. Larger files are compressed while smaller files are simply filtered.
- Fault tolerance refers to the issue of how important it is for the search engine index to be reliable.
- Lookup speed is exactly as it sounds, pertaining to how quickly a word can be found when the data is searched in the inverted index.
- Maintenance is an important factor as well because the better maintained a search engine index, the better it works.
Types of data structures
When a search engine index is being built, there are also many different types of data structures to choose from. Choosing a particular data structure for a search engine index is like deciding on a particular form for a web page, and depends on the factors that the search engine will serve. These data structures can be:
- Suffix tree – Supports linear time lookup and is structured like a Tree.
- Tree – An ordered tree data structure that stores an associative array where the keys are strings.
- Inverted index – Stores a list of occurrences in the form of a hash table or a binary tree.
- Citation index – Stores citations or hyperlinks between certain documents to support citation analysis.
- Ngram index – Stores sequences of length of data, which supports other types of retrieval. Sometimes supports text mini too.
- Term document matrix – This is used in latent semantic analysis. A term document matrix stores the occurrences of words in documents in a two-dimensional sparse matrix.
These different types come together with architecture and build a search engine index that is ready to use, and quickly returns the results that the visitor is looking for.

